Tesseract is an open-source OCR engine that was developed at HP between 1984 and 1994.It is an optical character recognition engine for various operating systems(Includes windows, linux and Mac).It is free software, released under the Apache License, Version 2.0, and development has been sponsored by Google since 2006.Tesseract is considered one of the most accurate open source OCR engines currently available.
This can be used effectively with Selenium for reading text from images, where sikuli may not be effective. Along with English, it also supports native languages such as Turkish, Spanish, Hindi, Swedish etc. This has typical architecture where we can feed the train data for the image recognitions.
The Process of integrating Tesseract OCR with java project is as below
Step1:
We need a JNA wrapper to use tesseract in our java project. We can use tess4j for this. It can be downloaded from here http://tess4j.sourceforge.net/
Step2:
Now extract the contents of the tess4j archive to workspace location.Step3:
From eclipse, Open the Tess4j project.

Now open a new project in eclipse and type below code:
import java.io.*;
import net.sourceforge.tess4j.*;
public class MySample {
public static void main(String[] args) {
File imageFile = new File(“<path of your image>”);
Tesseract instance = Tesseract.getInstance();
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
}
Step5:
Now expand the Tess4j project and expand source packages; inside you will find 3 packages. Copy all of them into your project’s source packages. It should now look like as shown below.

Here "OCR" is the project I created.
Step 6:
Right click on the project. Go to Build Path--> Configure Build Path--> Add external JARs.

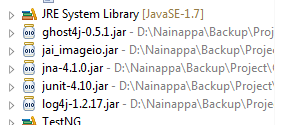
Navigate to the location where you extracted the tess4j archive. Open the folder (Tess4j) and navigate to lib. There you will see 4 jar files. Choose all of them and click open. Your project space should look like as shown below now.
Step 7:
Now you will find 2 dll files in the Tess4j folder (The folder which you extracted) namely liblept168.dll and libtesseract302.dll. Copy these two files into the src package and it should now look like as shown below.

Thats it…!!! You are done. When you run this code, it should display the text content in console window of Eclipse.
For far better results you can use MICROSOFT COMPUTER VISION API for OCR, it’s free for 5000 hits per month and 20 hits per minute but provides best results than others.
ReplyDeleteBelow is the link to the api
https://dev.projectoxford.ai/docs/services/56f91f2d778daf23d8ec6739/operations/56f91f2e778daf14a499e1fc
you can use the sample code from the API usage code for JAVA/JS etc.
which is available below on the given above link web page and try to use the HTTP client latest maven dependency for JAVA.
Hi I tried all instructions, but it is not working. Also, these files are not part of the Tess4J:
ReplyDelete1. netforge.net.vietocr
2. liblept168.dll
I am getting this error:
Error opening data file ./tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Exception in thread "main" java.lang.Error: Invalid memory access